8: Reinforcement Learning, part 5
May 11, 2025
So I wanted to test how the model would perform in a game with real players. Needless to say, it would’ve been much easier to show some metrics about how the model would’ve performed relative to itself before training (i.e. randomness). Yet, I still chose to take it against human players, and it performed terribly—somehow unable to dynamically choose cards to ask (this could either be due to a system bug or because the model was truly bad), causing it to repeatedly ask for the same card over and over again—and also having an insane urge to call set even when it doesn’t know what to call. So when I gathered five of my friends to play against it, we lost 9-0, with the agent having given away all its cards. So I went back to the drawing board and redesigned the entire architecture for picking actions given predicted cards.
The main idea is to create a neural network that is set- and player-agnostic. The problem with the previous model is that it had to learn the relationship between each card in the hand predictions and the card its asking for and player its asking form individually, for all cards and all players. It wasn’t able to generalize these relationships between input and output across all cards and players, which diminishes the usefulness of single datapoints. The new design, hopefully, does exactly that:
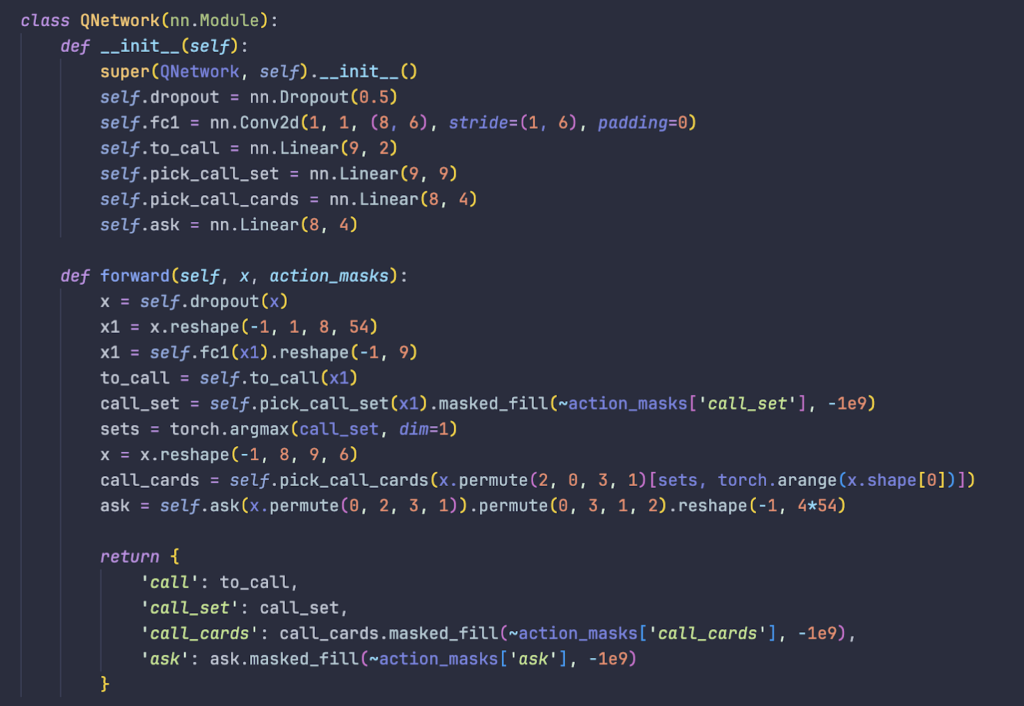
Let’s break it down!
x1 = x.reshape(-1, 1, 8, 54) reshapes the input, an array with dimensions of -1×432 (here, -1 substitutes for the arbitrary batch length) into one with dimensions -1x1x8x54. The first layer, misnamed as fc1, samples from each 8×54 matrix of the -1x1x8x54 at widths of 6 and outputs a single such value for that segment of 8×6, giving a matrix of -1x1x9 (there are nine 8×6 segments in an 8×54), which is then reshaped into -1×9 by dropping the extra dimension. Hopefully, this represented some information about the ownership of each set. This array of length 9 is then used to determine whether to call set! For a given call, the assignment of who has which card is produced via selecting the 8×6 segment corresponding most significant set of call_set from the predicted hands and doing matrix multiplication between the transposed 6×8 with an 8×4 linear layer to produce another matrix of 6×4 which hopefully corresponds to something about the ownership of cards for players on your team. The same concept applies for asking for cards.
To summarize, prior to these improvements, the input was a flattened -1×432 and we feed that directly into some layers to give another flattened -1×2, -1×9, -1×24, and -1×216. Not very smooth or demure. Now, its a dimensional -1x8x9x6 that drops and flattens dimensions to transform into -1×2, -1×9, -1x6x4, and -1x4x9x6. This allows for greater generalization, which should help the model learn better! And it seems to, as well—the model has demonstrated set-calling capabilities for the first time!
Leave a Reply
You must be logged in to post a comment.