Week 5: Earthquake Damage Assessment - Shaking Things Up
March 28, 2026
Hi everyone, welcome to my 5th week of the senior project! I did multiple things this week so there’s no central topic, I’ll just jump in!
The Damage Assessment Dataset
Last week I cleaned up the road detection dataset to deal with class imbalance. Time for the damage assessment dataset to get the same treatment so I can start training the models! Except not exactly.
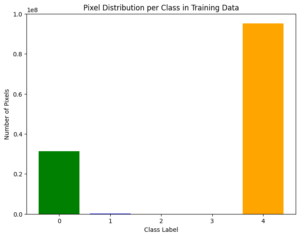
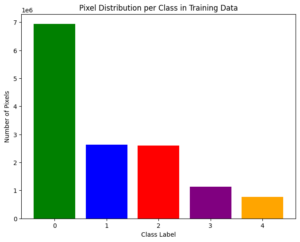
After analyzing the xView2 xDB dataset images and filtering for the ones that contained post-earthquake satellite images, I realized that I couldn’t simply adjust the representation of the damage levels since the amount of damaged houses were disproportionately low. In the image, the bar graph shows the pixel frequency of each damage level, undamaged (class label 0), minor damage (class label 1), major damage (class label 2), and destroyed (class label 3), along with many unclassified background pixels (class label 4). Since there were only 750 post-cropping images of the 2017 Mexico City earthquake, I couldn’t undersample the overly-undamaged images since it would reduce the usable dataset to around 100 images.
Assessing the UNet’s Damage Assessment
When I trained the UNet on the damage assessment dataset, I noticed some problems. In the initial pass, the UNet wasn’t good at recognizing damage at all. It seems like it couldn’t even learn the shape of buildings, and confused the similarly-gray street pixels for buildings instead.

I had actually initially continued using the Binary-Cross-Entropy and Dice loss as the loss functions (which were used in the road detection one), and one-hot-encoded the predictions. However, after reading the original paper, I switched to using cross-entropy, because BCE+Dice is used for binary tasks. For multiple classes, it’s reserved for detecting areas that have multiple overlapping classes, which this doesn’t apply to. This did help with making the learning curve more “normal”-looking, but the damage detection isn’t as good. The model seemed to only predict minor damage (blue). Luckily, it is able to discern some orderly large shapes as undamaged, which might be shown by the big white gap in the second image.

Next I suspected the issue may be the dataset itself, since the resolution of this dataset (0.5 m per pixel) is noticeably lower than the road detection dataset (0.3 m per pixel) [4], and I couldn’t even visually discern the between damaged and undamaged myself.
SegFormer Results
With this in mind I tested if a different model would be able to learn from this dataset. I chose a SegFormer since its architecture is the most different from UNet than DeepLabV3 (learn more about them in my 3rd week’s post!), and most likely to be successful, due to it being a transformer, based on results from similar studies comparing the two. [4]
I first used a pre-trained model, the nvidia/mit-b0 SegFormer [5], which is pre-trained on a small set of ImageNet images. The difference was day and night. The SegFormer was not only able to discern the shapes of houses from roads, but also accurately outline the correct damage levels. I think due to SegFormer’s transformer architecture, it was able to capture more context for the objects it is segmenting, thus learning more features needed to discern damaged from undamaged houses. This is a strong start, and I’ve also ruled out that the dataset is the problem preventing the U-Net from learning!

Revisiting the UNet
I tried adjusting the architecture of the UNet, but to little success. I tried using a UNet with a resnet50 backbone, (resnet50 is a version of ResNet, or Residual Network, that uses “skip connections” to jump over layers in deep learning), but there wasn’t any improvement. Then, I looked at other UNet implementations online to find that others used Batch Normalization while I hadn’t. Batch normalization normalizes the input activations of each layer of the neural network, which makes the model learn more easily. That is likely what I am going to implement next.
My questions for you, viewer, are the following. How likely is the UNet to improve with Batch Normalization? Is there anything else I can do about it not learning features? Another less related question: I’ve also realized my method of re-balancing imbalanced classes last week involved creating a new drive folder with all the images that show the minority class, and the data loaders split the train and test dataset using that drive folder of filtered images. Would using the drive folder for the validation or test part of the dataset impact the accuracy of my model’s evaluation scores? Is there a way to allow the validation to use a different set of images without having to scan every image while splitting the train and validation datasets?
Works Cited
[1] Gupta, Ritwik, et al. “XBD: A Dataset for Assessing Building Damage from Satellite Imagery.” ArXiv:1911.09296 [Cs], Nov. 2019, arxiv.org/abs/1911.09296.
[2] Can Ekkazan, and M. Elif Karslıgil. “TE23D: A Dataset for Earthquake Damage Assessment and Evaluation.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, Institute of Electrical and Electronics Engineers, Jan. 2025, pp. 1–12, https://doi.org/10.1109/jstars.2025.3526088. Accessed 21 Oct. 2025.
[3] Lin, Szu-Yun, et al. “HaitiBRD: A Labeled Satellite Imagery Dataset for Building and Road Damage Assessment of the 2010 Haiti Earthquake.” Designsafe-Ci.org, DesignSafe-CI, Dec. 2023, https://doi.org/10.17603/ds2-fqat-4v02. Accessed 28 Mar. 2026.
[4] Shao, Yang, et al. “Deep Learning for Remote Sensing Mapping of Roads, Sidewalks, and Bicycle Lanes in Bogotá.” Remote Sensing Applications: Society and Environment, Elsevier, Mar. 2026, p. 101993, https://doi.org/10.1016/j.rsase.2026.101993.
[5] Xie, Enze, et al. “SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers.” ArXiv:2105.15203 [Cs], Oct. 2021, arxiv.org/abs/2105.15203.
Reader Interactions
Comments
Leave a Reply
You must be logged in to post a comment.
Hi Yujie! I’m really glad you were able to make some significant progress with the pre-trained SegFormer model! It seems like it was able to distinguish the damage levels a lot clearer. It’s a super great start, but I was just wondering whether you’d be creating your own SegFormer model instead of using a pre-trained one in the future? Perhaps that would make it more personalizable to your specific damage-assessment goal? I’m excited to see the next steps you take!
Hi Chloe, thanks for your insight!
This is definitely a direction I want to take after I finalize the comparison of all three models. I’ve already tried taking away the pretrained checkpoint and the SegFormer still outperforms both UNet and DeepLabV3+. However the SegFormer I’m using is just one imported from the transformer library (SegformerForSemanticSegmentation), so I will see if there’s a way to build my own!
Hi Yujie, have you considered building your own dataset to remedy the lack of damaged houses? What you could do is go use Google Earth Engine to “go back in time” to specific earthquakes, and download imagery for that. Your progress looks great otherwise!
This is definitely useful! I think should be glad I found pre-defined datasets with labels that are more balanced so quickly. 🙁 I’ll definitely think of using this strategy later when optimizing my models if I need more data (because currently I have 352 images, which is sufficient but could be better). When you use Google Earth Engine, do you have to manually label your data? What programs do you use to label your data?
Such a fun read this week, Yujie! It’s wild how much ground you covered, from switching datasets, testing out a whole new model, to still circling back to troubleshoot the original one. The jump in results between your two models looks really dramatic, too. I hope the next round of edits gets the first model up to speed as well!
Thanks! Yep, the difference is big between transformers and non-transformer models. It might be unfairly biased because the Segformer is pre-trained and an imported library, however.