Week 9: Burnout
May 3, 2024
Hello my benefactor. If you’ve followed me for this long, and you’ve read all my blogs, I want you to know that I appreciate you. You’ve been my companion through my highest highs and lowest lows in this endeavor that is my Senior Project. Though I don’t know your name and I’ve never seen your face, I thank you for being a faceless beacon of motivation.
Hmm. So. Over the past week, I’ve been pretty locked in, working on a lot of different aspects of this research project. But I’ve found that none of them are interesting or substantial enough to talk about…perhaps it’s a metaphor for life. Each and every day we take on so many pursuits — getting out of bed, brushing our teeth, eating meals, walking around — but when we sit down at the end of the day, we can still sometimes feel so unproductive, so unachieved. If only we could value our each and every second, our each and every action, wouldn’t we feel so much better about ourselves?
And with that mindset, I’ve settled on talking about my explorations in the world of training data manipulation. If you imagine a machine learning model to be a student studying for APs, the training data is the study materials the student uses, and the accuracy of the model is the resulting AP score the student gets. Obviously, if the machine learning model is fed bad learning materials, like a student studying for AP Physics 1 by binging Big Bang Theory, it’ll perform poorly.
This week, I’ve been trying to feed the AI model different learning materials — Barron’s, Princeton Review, Khan Academy — and seeing how the results pan out. In total, I tested four different training demographics:
(1) Lower Dropout — so technically in this situation, I didn’t really manipulate the learning materials, I mutilated the student’s brain instead (changed the machine learning model architecture). So in a lot of machine learning programs, programmers add a thing called dropout, which essentially makes the machine learning model forget a random selection of the stuff it’s learned. You must be thinking, that doesn’t make much sense, why would you want your model to forget the stuff it’s learned?
I’m sure there’s a complex mathematically rigorous explanation, but essentially it’s to prevent this thing called overfitting where the machine learning model fits too well to training data while the training data is not necessarily representative of all possible data demographics, hence lowering general accuracy.
In my initial machine learning model, I had a dropout of 0.2 after each convolution layer, meaning I would essentially make the model forget about 20% of the knowledge it learned and make it relearn it through new training data. I lowered that value to 0.1.
(2) More Uniform Training — ok the previous section was a little bit too jargony and long, so I’ll make this one brief. Essentially, instead of having a more limited demographic of streaks in my training data, I showed it all different kinds of streaks, extremely short and faint ones, extremely bright and long ones, everything.
(3) Centered Streak Training — initially the streaks that I used to train the model had their center within 5 pixels (Manhattan distance) of the center of the 80px by 80px image. I reduced that value to 1 pixel.
(4) Fewer Hard Negatives — hard negatives are images where streaks are implanted in both the science and reference image (you can refer back to Week 2 for a concise definition of these terms). I reduced the number of hard negatives, increased the number of regular negatives, and kept the number of positives the same.
And here are the results (ignore the red dots). Week 5 blog explains in detail how to interpret this graph, but essentially the higher the line, the more accurate the model.
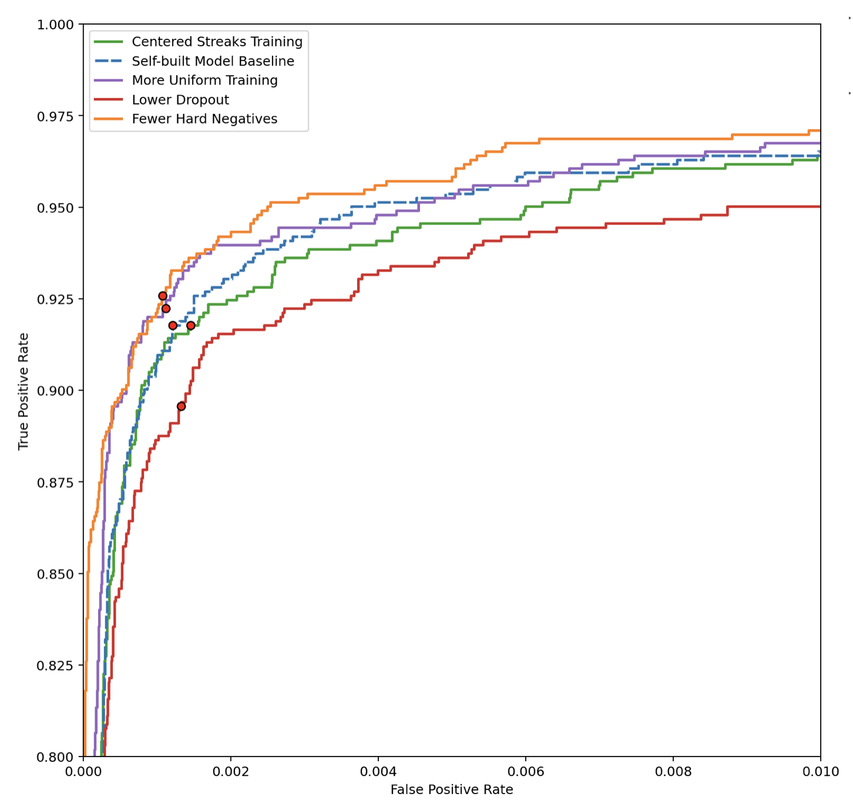
Well, looks like the “fewer hard negatives” model scored the highest on their AP exam. Over the next week, I’ll probably apply this model to real nights of data and see how it does.
You know it’s a sad thing in observational astronomy research — you can develop a great technology, but no one gives a damn until you get substantial results. I’m not burnt out, you are. I’ll see you all soon.
Leave a Reply
You must be logged in to post a comment.