Week #8: Updates on data
April 24, 2025
Welcome back! I just came back from spring break, but I’m so excited to share with you guys everything that I’ve worked on this week. This week, I finally completed data collection and finished organizing and coding my machine learning program.
In the previous blogs, I always talked about gathering data, but unfortunately, because there were so many breakages in my data collection, I started over. As a recap, I’m gathering threshold voltage (vt) data based on an SSD cell’s location and age. To speed up the aging process, my external advisor and I baked the disk that we were using to mimic 2 days of data over a much shorter period of time (like 4 hours). Therefore, I collected my location, age, and vt data every 4-6 hours. Luckily, nothing happened to the disk that I was gathering data from this week. By the end of the week, I had collected 4 substantial samples of data. Yay!
Like in the previous blogs before, I combined and organized my data into 4 features:
- hours elapsed
- block number
- die number
- wordline
The next step is to organize thousands of lines of data into clusters. This week, I switched back to K-means clustering because I learned a technique called the Elbow Method to determine the ideal number of clusters.

According to the Elbow method, the number of clusters where the graph starts to flatten out is the most ideal. Therefore, I ended up choosing 5. By using this method, I realized that the number of data points in each cluster was more even.
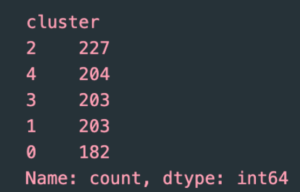
Ok, now I’ve FINALLY completed the clusters. Now, how are we going to predict the vt?
Let’s say a data point is 8 hours old, is located at block 159, die number 8, and wordline number 32. The K-means clustering algorithm is going to fit this data point in one of the formulated clusters, and the predicted vt is going to be equal to the average vt of the existing data points in that cluster. Finally, to grade the algorithm on its accuracy, we compare the predicted vt with the actual vt.
Next week, I’m really hopeful on coding the machine learning algorithm so that it will improve itself based on the accuracy score of the predicted vs. actual vt. I’m sure you know that data collection took a lot of time, but it’s also important to accept that sometimes, things don’t always go your way and that’s ok! I don’t really see my previous attempts as worthless because I gained deeper knowledge in SSDs and coding every time. There are only 2 weeks left in my senior project! Let’s continue to work hard together. I’m really excited to see my project slowly come together. See you next week!
Leave a Reply
You must be logged in to post a comment.