2. Preliminary Tests
March 12, 2026
Another week has flown by! Here’s some more background for my project and updates on my progress.
Formally Categorizing Hallucination
For my project I will be adhering to the definitions of hallucination outlined in this survey paper by Huang et al. We can divide hallucination into extrinsic (outputs cannot be verified by external sources) and intrinsic (directly conflict with external sources). In other words, extrinsic hallucination is when the model generated a plausible-sounding answer to a prompt that should be unanswerable. Meanwhile intrinsic means the model is spewing factual inaccuracies when a correct answer exists. Within the division of intrinsic hallucination, we can further divide into factuality (inaccuracies) and faithfulness (unable to execute faithfully) hallucination.
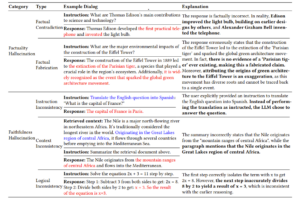
As you can tell, there are a lot of different categories of hallucination. Yet these taxonomies are adopted with a human-centric view in mind, relying on subjective interpretation. So how do we define hallucination objectively to implement in code?
The first most obvious method is by repeatedly sampling answers to questions with answers in a dataset, like TriviaQA or math questions. We can then classify the errors based on how frequent the LLM correctly answers the question.

Another way is similarly based on model confidence. However, this method employs another natural language processing (NLP) model for a more comprehensive statistical (instead of categorial) error description. A past project I worked on used this method, which is why I’ll go into it in detail. Farquhar et al. proposes semantic entropy in this article published in Nature, a method that aggregates token-level uncertainties across clusters of semantic equivalence. To calculate semantic entropy for a given query x, we sample model completions from the LLM, aggregate the generations into clusters (C_1, . . . , C_K ) of equivalent semantic meaning, and then calculate semantic entropy by aggregating uncertainties within each cluster. It can be determined whether two generations have equivalent semantic meaning using natural language inference (NLI) models to predict entailment between the generations, with two generations being semantically equivalent if they entail each other. Each generation is added to existing clusters if semantically equivalent. Otherwise it gets added to its own cluster.
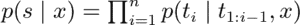
The probability of the semantic cluster C_i is then the aggregate probability of all possible generations belonging to that cluster.
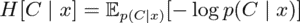
To estimate this value, Farquhar et al. treated the K generated clusters C_1, . . . , C_K as Monte Carlo samples from the true distribution over semantic clusters p(C | x). So the approximation for entropy becomes
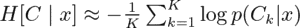
As you can tell, this second way is way more long-winded!
Detection and Mitigation Methods
So how exactly can we detect and mitigate hallucination according to past research? I’ll go over some of the methods I found in my literature review.
Detection: Many papers train probes on representations to predict hallucination, like HaloScope and LLMsKnow discussed below. Park et al. created a Truthfulness Separator Vector (TSV). The TSV is a lightweight and flexible steering vector that reshapes the LLM’s internal representation space during generation to enhance the separation between truthful and hallucinated outputs. Li et al. proposed simulating the human process of signal perception to create LLM hidden layer temporal signals, which are then mapped to construct spectral features through a Fast Fourier Transform. These features are used to capture anomalies from LLM reasoning, increasing hallucination detection accuracy. Chuang et al. created Lookback Lens, a generalizable linear classifier based on the ratio of attention weights on the context versus newly generated tokens, that performs as effectively as more complex models. Wang et al. proposes looking at the feature distribution of the Chain-of-Embedding (CoE), which can be thought of as the latent thinking path of LLMs.
Mitigation: Some research suggests changing prompting strategies, such as encouraging chain-of-thought (CoT). HaluSearch by Cheng et al. introduces a hierarchical thinking system switch mechanism to help a model switch between thinking speeds to reduce hallucination for more complex prompts. Many mitigation works focus on large vision-language models. Wang et al.‘s method suppresses the influence of visually absent tokens by modifying latent image embeddings during generation. Chang et al. partially generates answers and identifies hallucination-prone tokens during generation through a monitor function. Then they further refine these tokens through a tree-based decoding strategy to prevent hallucinated answers.
Future Steps: I know it’s strange that I’m putting future steps before updates! I found a lot of the aforementioned work in the GitHub Repo Awesome-Hallucination-Detection-and-Mitigation. Each paper also has its code, so I’ll be looking into more detail in those like I did for the two repos outlined below. Then, I hope to start implementing fragments of what I think will work best together for my unified detection and mitigation framework.
Updates
I’ve been trying to replicate the results from various open-source GitHub repositories that internally probe for hallucination. First, I set up using wandb tracking which was very helpful for tracking my runs. I first tackled the GitHub repository for the paper “HaloScope: Harnessing Unlabeled LLM Generations for Hallucination Detection” by Du et al. This repository aims to give a membership estimation score for distinguishing between truthful and untruthful generations within unlabeled mixture data. It also identifies the best subspace of latent space for probing by performing Singular Value Decomposition to find the primary directions of variance. I quickly ran into a multitude of environment issues. It didn’t help that the “issues” tab of the repository showed others having the same issues. Nonetheless, I still was able to learn from the code. It used the Baukit Python library which looks really useful for writing a framework that investigates an LLM’s internal activations.
Then I moved on to run the GitHub repository for the paper “LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations” by Orgad et al. It trains binary logistic regression probes to detect hallucination. Its framework includes generalizability tests across datasets and customizability on which layer or token should be extracted. The first step would be to generate answers from an LLM. My computer includes a 4 GB RAM GPU called the Quadro T1000 with Max-Q Design. However, it could not load the Mistral-7B models for answer generation.
Then I modified the code to be able to use Gemma-2b, which should be much lighter. However, generation was extremely slow. My GPU ran out of memory, which was incredibly frustrating.

So given my failure with running these repositories, I decided that I will instead work on understanding and replicating the code into a Jupyter notebook in Google Colab, where I can access more powerful GPUs.
That’s it for this week’s blog post! Typing everything out made me get a clearer sense of what I was working with too, and I hope you learned something too! Excited for another week.
Leave a Reply
You must be logged in to post a comment.