Week 4: Breaking Down Computers and Teeth
March 26, 2024
This week, I have not only started to break down the math operations in BSI but also my computer and my teeth. I got my last two wisdom teeth removed (hoping to never see another numbing needle again) and suffered most of the week, so this week’s blog will mostly be to catch you up on my prior research. As for my computer, after restarting the build process several times, I decided to put the build on hold and pivot my attention to tweaking the BSI library, only to discover that somewhere in my build process, I accidentally changed an important environment variable which now makes my BSI build also fail. In conclusion, until I can figure out which variable I changed, I’m stuck with either using a different computer or just focusing on the math part. Sorry, computer.
Building on Windows
After witnessing countless failures on my MacOS related to OpenMP, I decided to try my hand at building OpenSFM on my Windows computer instead to see if it really is more straightforward.
For those of you wondering why OpenMP is such a big issue, Apple disabled Clang support for OpenMP (probably out of pure malice to ruin my efforts), so you have to go the long way and install a version of LLVM based on your Clang version. The shortest explanation I found has been on this project. I haven’t tried the installation on the website yet because I’m not completely sure how reliable it is, but I will probably investigate it further sometime later.
Now, to Windows.
I first tried installing the Windows Subsystem for Linux (WSL) so that I could have Linux because my external advisor was actually able to build OpenSFM on his Linux computer. However, I ran into this error opening it and haven’t yet had the time to figure out what went wrong because it isn’t one of the named errors in their installation FAQ.
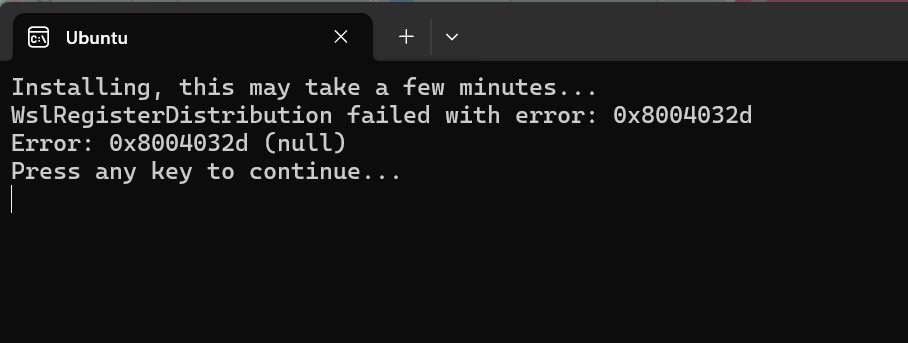
On the regular Windows command prompt, one new error which I did see on MacOS but forgot to mention is this:
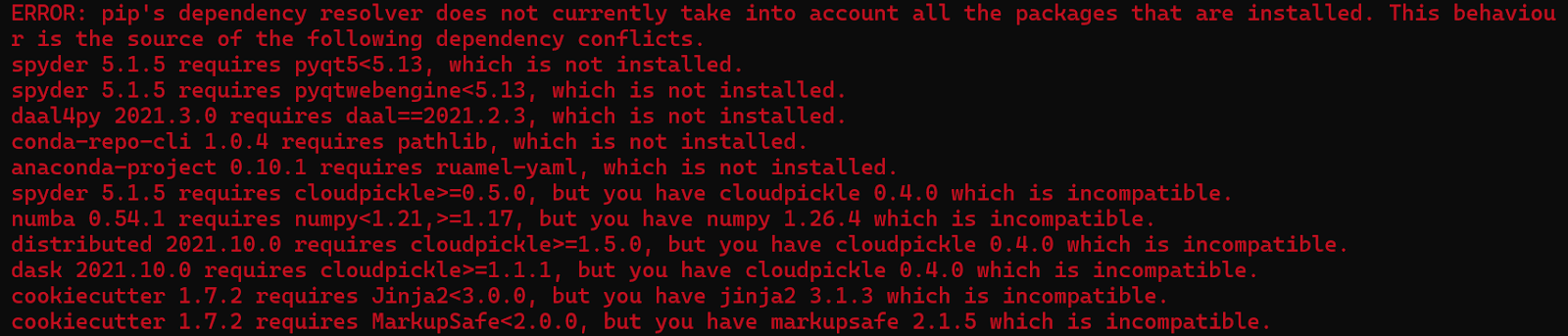
On MacOS, I installed all the dependencies it was returning an error for, so I didn’t see this error again. On Windows, I decided to ignore the error to see if it would cause any future problems. So far, I am getting some ModuleNotFoundError’s so the next thing I’m gonna try is fixing those dependency errors.



Bit-Slice Indexing (BSI)
Now that we’re here at the math part, let me run through the basic algorithm behind bit-slice indexing. Indexing is a technique to speed up data retrieval and query processing. The two types I’m going to talk about are bit-slice indexing and bitmap indexing.
Bitmap indexing creates integer indices where the bit values represent the presence of each element. For example:
Bitmap Blue Fruit Vegetable
101 1 0 1
001 0 0 1
010 0 1 0
This makes for very fast evaluation of boolean expressions.
Bit-slice indexing uses bitmaps to encode its values, where the dataset is partitioned into slices of its binary representation. For example:
Number Binary Representation Slice 3 Slice 2 Slice 1
1 001 0 0 1
5 101 1 0 1
7 111 1 1 1
Slice 3 is encoded as bit-string 110 = decimal number 6
Slice 2 is encoded as bit-string 100 = decimal number 4
Slice 1 is encoded as bit-string 111 = decimal number 7
Bit-sliced indexing is preferred for operations like addition and multiplication.
Hybrid BSI
Data compression is the technique of reducing file size and saving storage by encoding large amounts of data using fewer bits.
One such technique is the Word Aligned Hybrid (WAH) compression for bitmap indices. WAH represents bitmaps using two types of words, filler and literal, indicated by a single bit at the beginning of each word. Literal words are chunks of length w – 1, where w is the length of a word on the local computer, in the bitmap that are represented verbatim. Filler words compress consecutive groups of zeros and ones, where one bit is used to represent the fill value (zero or one), and the rest of the w – 2 bits represent the run length (how many times the fill value repeats). For example:
If w = 8, and verbatim words were represented by 0, filler words by 1,
10000101
could be encoded as
11000001 10000100 0101
(Word 1: 1 repeated 1 time,
Word 2: 0 repeated 4 times,
Word 3: 101)
Since this framework divides bitmaps into groups of w – 1 bits rather than w bits, this causes some misalignment, which needs to be resolved at query time.
Enhanced WAH (EWAH) solves this issue by introducing a new type of word in place of filler words, a marker word. The upper half of a marker word is used to encode the fill value and the run length. The rest of the marker word is used to represent the number of literal words following the run length. Since this implicitly determines the order of the words, no bits are required to explicitly encode the type of the word. Using the same example from WAH:
10000101
could be encoded as
10010000 01000001 101
However, if the data is not sparse enough and there are no patterns, it is usually better to store it verbatim. In order to perform operations between compressed and uncompressed without built-in support, one would have to decompress the compressed data, which causes a lot of overhead, the runtime cost of decompression.
The problem with current implementations of BSI is that there isn’t support for operations between compressed and uncompressed. To confront this issue, Professor Guzun has proposed hybrid BSI. Using the EWAH compression scheme, hybrid BSI would implement operations to return results without decompression. To do so, when reading in two different BSIs, there are 3 scenarios that need to be handled at each word: compressed and compressed, compressed and uncompressed, uncompressed and uncompressed. Through testing and analysis, we have proved the value in saving overhead through this technique by comparing the runtime of our operations with that of PyTorch tensors, which are optimized for machine learning models to run on GPUs and other specialized hardware. Now it’s time to show another application by comparing its runtime to NumPy arrays, which are optimized for matrix operations on large amounts of data.
Look into the future
Here’s what the schedule for the future looks like:
Week 5: Investigate best way to quantize decimals and multi-dimensional BSI
Week 6: Implement quantization
Week 7: Test quantization
Week 8: Try using same numpy algorithms for BSI for bigger operations (determinant, inverse, etc.)
Week 9: If succeeded last week, try for rest of algorithms, else setup conversion from BSI to numpy
Week 10: Write drafts of smaller operations in BSI (drop col, etc.)
Week 11: Runthrough with OpenSFM and collect some data
Week 12: Make presentation
Sources:
https://mac.r-project.org/openmp/
Guzun, G., Canahuate, G. Hybrid query optimization for hard-to-compress bit-vectors. The VLDB Journal 25, 339–354 (2016). https://doi.org/10.1007/s00778-015-0419-9
Leave a Reply
You must be logged in to post a comment.