Week 10 (4/28-5/2) - Implementing Fine-tuning, Building the Web App, and GPU Limits
May 1, 2026
Welcome back to my blog! This week had both exciting developments but also the runtime problems I had anticipated last week. I ran the fine-tuning stages for BioMistral, got a working demo of the web app up, and ran into many computational constraints.
My first priority this week was running the Stage 1 fine-tuning (on the MIMIC dataset). I started with 2 epochs to get a baseline sense of how the model was behaving.
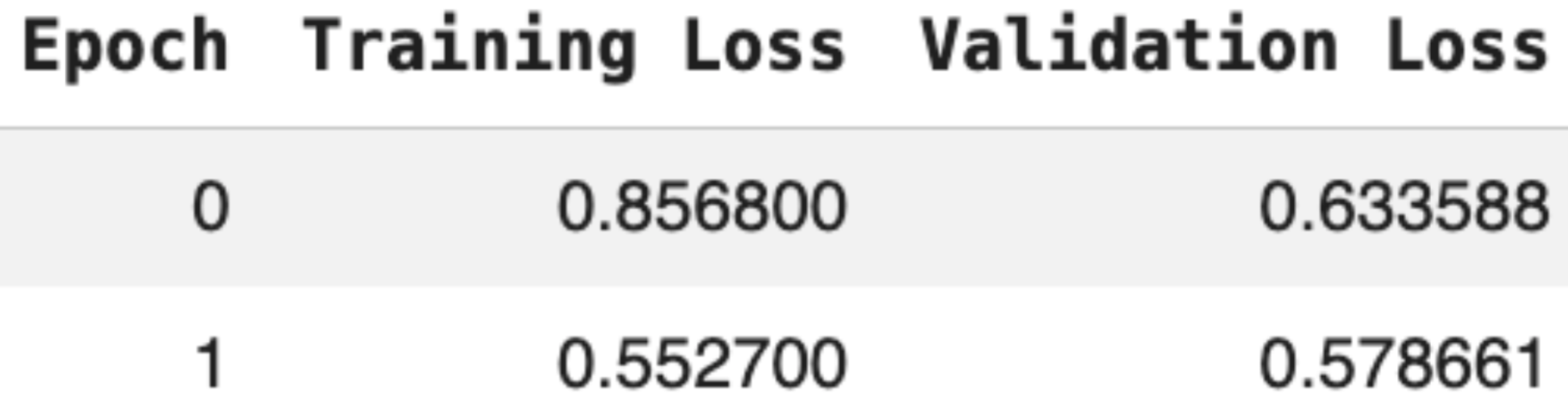
The results were promising enough to push forward, so I decided to try 5 epochs to see if the model could squeeze out more learning without overfitting. The training and validation loss curves were promising, as both were decreasing. The larger drops and lower values for the training loss in comparison to validation loss (which was starting to stagnate) is something I plan to keep an eye out for, as this could be an early sign of overfitting, which is why I limited the number of epochs at this point. The image below only shows 4 epochs as the last batch (due to the number of rows in MIMIC) was not the same size, and so its output doesn’t get printed in the table as it doesn’t register it as a “full epoch” (though the training happened). I then got a first look at some example outputs from Stage 1!

The format and general clinical domain are solid, but the predictions are noticeably more vague compared to the ground truth. This actually makes a lot of sense given the constraints: MIMIC is a small dataset, so there’s only so much the model can learn from it alone. The specificity should improve significantly once Stage 2 and RAG are integrated, as those will ground the model in the actual clinical guidelines. One specific example was that the model predicted morphine as a treatment but missed LORazepam, a sedative. Without context about the specific trauma (a car crash) or what the patient likely presented like in the moment, the model couldn’t have reasonably predicted that one. Morphine for pain management post-surgery is still a reasonable clinical call, so this is still a good sign that the model is thinking in the right direction (though imprecise).
Moving onto Stage 2, things got complicated. I ran into GPU limits midway through training, which halted progress entirely while I waited for them to recover. Unfortunately, the GPU limit hadn’t reset a day or two later. So, after some research, I decided to pivot to Kaggle Notebooks, which has been a much more reliable environment. It has 30 hours of GPU time per week that resets weekly, access to the same GPUs, and wouldn’t stop mid-runtime like Colab would if I ran something overnight.
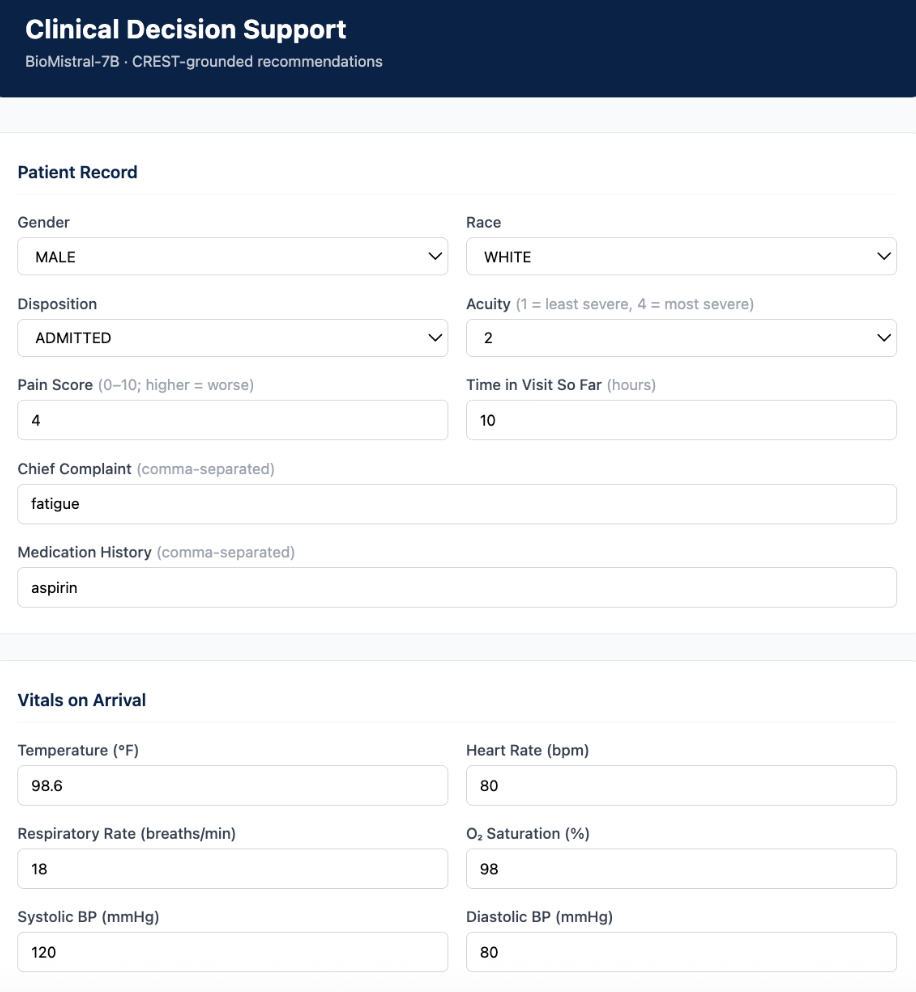
While dealing with the GPU situation, I also created my web app, which I had planned to start building in parallel. I created a PLAN.md file to vibecode the full webpage, which connects the predict() function in the pipeline notebook to the backend. The architecture uses a Next.js frontend, and to run the site, you run the final pipeline notebook, which prints an ngrok URL that gets added to the environment, and then launches a Docker container. Though a new URL is needed each time the website is launched, this should be fine for a demo.
I first built a dummy hardcoded version just to get a sense of how everything would look and feel before the model was fully connected.
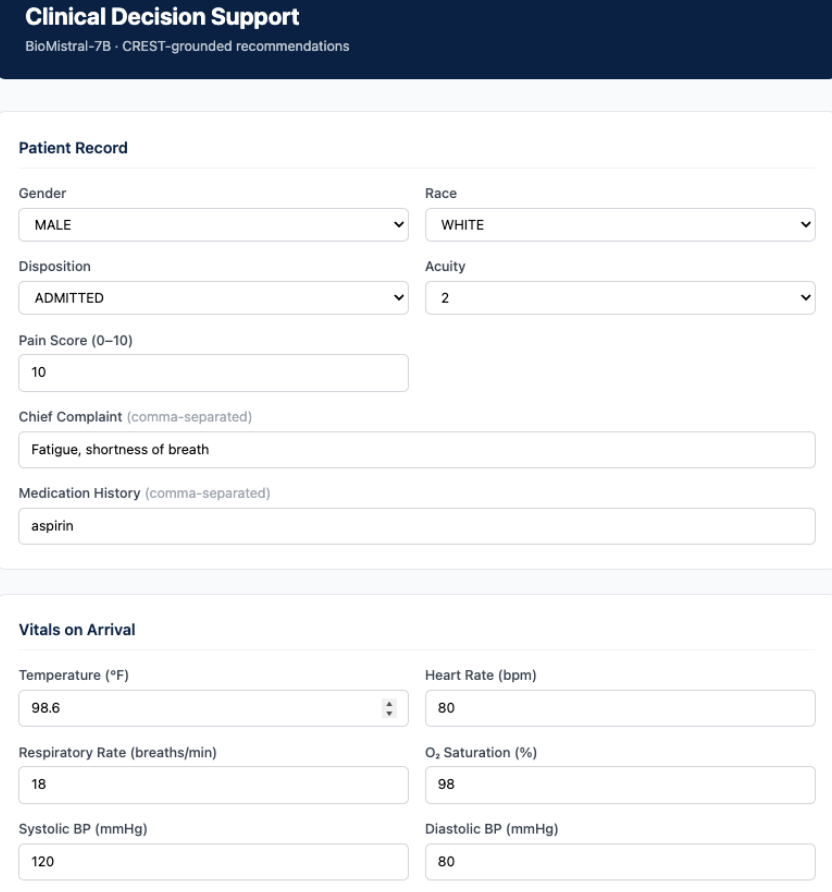
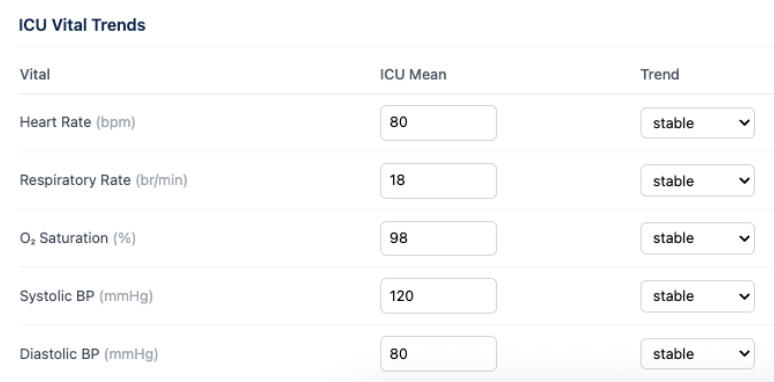

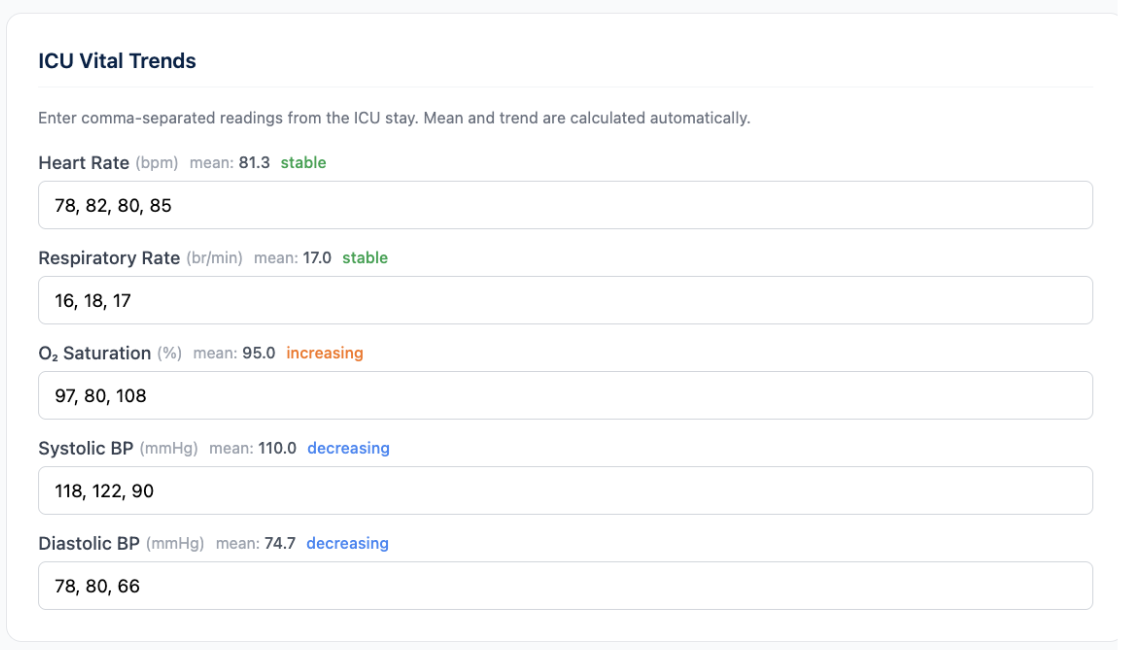
Overall, the original dummy version looked really good. There were a few issues to clean up on the input side: fixing the race options, verifying the disposition and acuity options. After discussing with my external advisor Dr. Maecker, I also decided to switch vitals from mean and trend format to a direct list to make input easier. The updated webpage looked great, and I’ll make sure to revisit it again next week when I get my LLM to work.
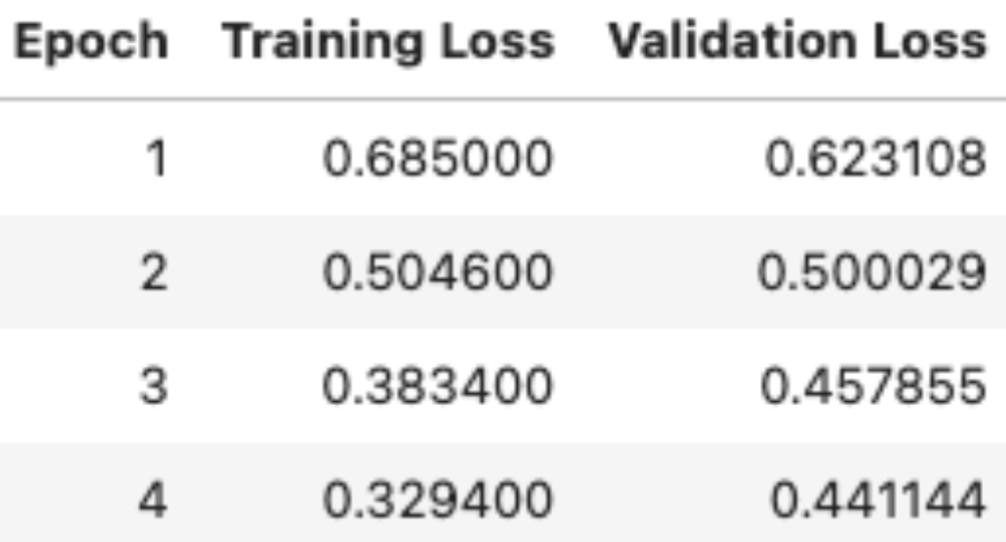
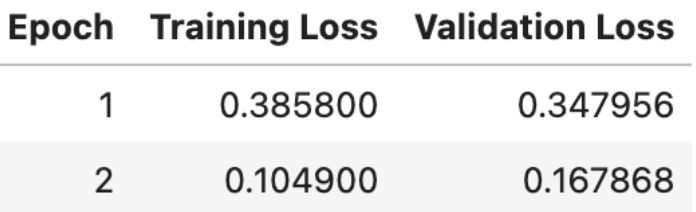
As for Stage 2, the results from my first run unfortunately didn’t save, which meant rerunning from scratch. Watching the loss curves more carefully this time, I noticed the model was overfitting at 5 epochs (training loss dropped sharply while validation stagnated), so I brought it down to 3 epochs and am considering trying 4 next (the image below only shows 2 epochs for the same reason I mentioned above). Unfortunately, when I went to run the full pipeline, I realized I hadn’t properly saved the adapters (the fine-tuning) from previous notebooks, meaning I will have to rerun everything this weekend and properly save the results. While this sort of setback is frustrating so late in the week, using Kaggle has still been extremely helpful and I’m glad it’s a quick fix.
I’m also thought about evaluation now that real outputs are close. A few approaches I considered: finding a test set with established “gold standard” answers to compare predictions against, sending input-output pairs to Dr. Maecker for a more expert review, and building a custom rubric around safety, actionability, and clinical appropriateness. Discussing with Dr. Maecker, I’ve decided to follow both of the latter options: making sure to look at all three tenets when considering the outcomes of the model. Here is a more detailed description of each tenet:
- Safety = How safe the suggested treatment is and the balance of risk (how the suggested treatment could affect the person taking into account the actual chance of the potential diagnosis)
- Actionability = How vague or specific the suggested next steps are (whether confirming diagnosis or providing a treatment)
- Clinical appropriateness = Ranging from correct, partially correct, reasonable but suboptimal, or incorrect, it would detail overall how appropriate the treatment is for the patient
For next week, I plan to evaluate the outputs using the rubric above, and even consider hyperparameter tuning, though computational limits will constrain how much I can do this. If I am able to, I hope to optimize the learning rate and LoRA rank (essentially the amount of parameters of the model we are reevaluating (from pretraining) with fine-tuning). If you’ve done hyperparameter tuning under tight compute budgets, I’d love to hear how you prioritized what to tune and when to stop. Stay tuned for next week!
Reader Interactions
Comments
Leave a Reply
You must be logged in to post a comment.
Hi Aanya, great work this week! The UI of the app is extremely clean, and it looks very professional. Have you considered making it available online (with something like Vercel or Hugging Face)?