Week 9 | P = 0.061!!
May 4, 2023
I can’t believe we’re nearing the end of the blog and my project! Collecting the data and seeing my results have been so gratifying these last two weeks :D. As anticipated, the Fed recently released a huge document with their own findings and review of their banking regulatory measures, specifically regarding the regulation of SVB. I am still going through the massive 118-page pdf, but their main findings thus far are:
- SVB’s Board And Management Failed To Manage Risks
- Supervisors Failed To Address Problems + Vulnerabilities As The Bank Grew
- Stronger Regulatory Framework Is Required Form The Fed
The report basically affirmed a lot of the explanations for why SVB failed. The bank’s portfolio was growing super quickly but its liquidity and the Fed’s regulations were not keeping up. One proposed solution is a faster transition to heightened regulations when a bank’s portfolio grows. The Fed is also creating a dedicated novel activity supervisory group, aimed at monitoring risks that may have fallen under the radar. In addition, the report suggested greater capital or liquidity requirements in certain cases.
Overall, the report is mostly addressing issues regarding governance and regulation whereas my research is looking at clientele behavior. I believe both sides should be examined when understanding and studying a bank run just because it can tell us the full picture of what went wrong and give us multiple angles to address the issue. It was pretty amusing to read in the report that any proposed changes, such as those to stress tests and capital requirements, wouldn’t even come into effect until years later. How many more banks will collapse due to interest rate risk as a result??
Sigh, even First Republic went down the beginning of this week. And all of these collapses just keep coming back to the Fed’s interest rate hikes. Everyone is trying to examine what went wrong and how to prevent it from happening again, but what if there’s not even a solution to combating these high interest rates?
That is beyond the scope of my project but just some food for thought ;).
Back to my project…
I spent this week organizing and analyzing my data on excel. I was also able to pay all participants with their bonus. It totaled to $71.06 for all three treatments.
In each treatment, there were 7 groups of 5 participants each, and all of the public accounts failed. This meant I never had to utilize the chance error of bank failure (unfortunate, because I wanted to run my random number generator). It also meant I never had to consider the multiplier, or interest rate, in any of my calculations.
Data Analysis
For preliminary analysis, I was primarily concerned with the average number of tokens taken out by each group and individual. There was definitely a trend going on.
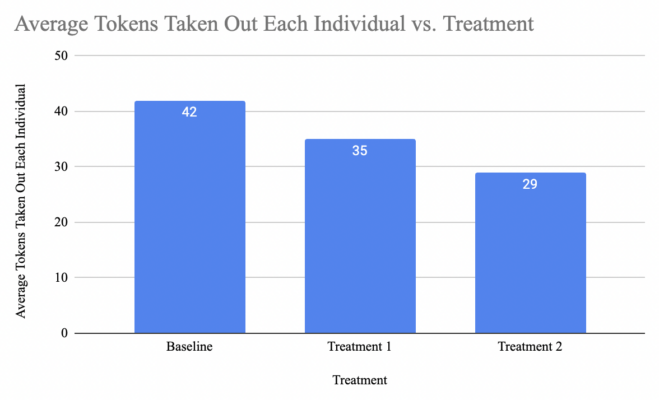
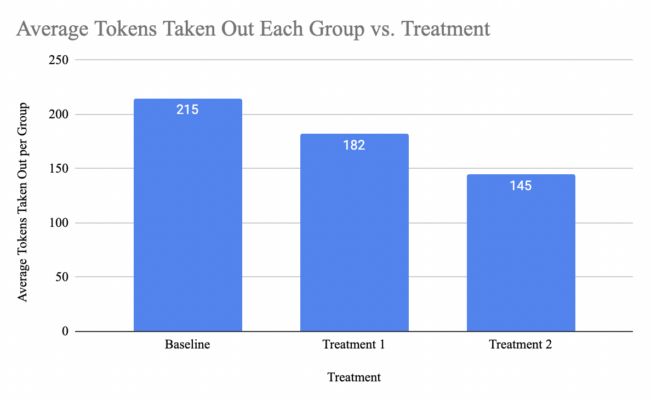
From now on, I’ll be referring to the No Government Protection treatment as the Baseline, FDIC Insured as Treatment 1, and Government Protected as Treatment 2. From the chart, we can see how participants were taking less tokens out as they were guaranteed their deposits back.
Next, I looked at the number of participants who took out 10 tokens or less. In my experimental design, 10 is sort of the threshold for most tokens each participant in a group can take out to ensure that the bank does not fail.
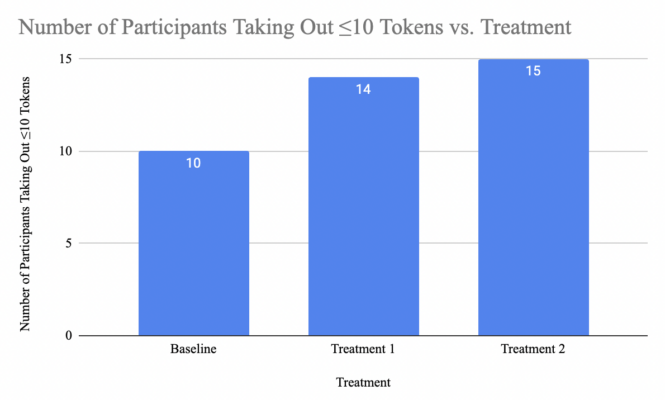
I wouldn’t say this is that apparent of a trend, but it’s still there as a reference. More people are being conservative with the amount of tokens they choose to take out as they are insured with more money.
T-tests and Linear Regression
Now on to some more in-depth statistical analysis: t-tests and linear regression.
I did all of these on excel (<3), which was super convenient as I just had to organize the data and then let excel do the math.
I ran 3 t-tests, comparing Baseline to Treatment 1, Baseline to Treatment 2, and also Treatment 1 to Treatment 2. The t-test is basically just a way to compare the mean of two datasets. So earlier I showed a graph of the average number of tokens taken out by individuals in each treatment. The t-test is basically seeing whether those differences are caused by a difference in treatment or not.
Each t-test yields a p-value, which tells me how likely the results are due to chance. For the purposes of my experiment, I will be using an alpha level of 0.10. In the t-test comparing Baseline to Treatment 2, I got a value of p=0.061, which means that I can reject the null hypothesis!! There is a significant difference in the participants’ behavior when the entirety of their deposits are protected.

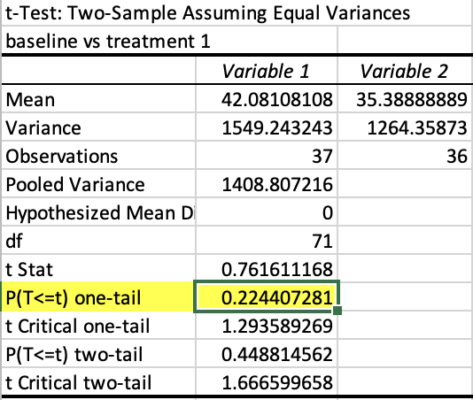
I want to explain why I chose to use the one-tail test instead of two-tail. The one-tail t-test obviously yields more significant results, but I figured it was applicable to the purposes of my study since I just wanted to see if the treatments would yield any change to withdrawal behavior. The two-tail test cares about directionality, so it considers the possibility that the treatment would lead to both a worsening and improvement in the number of tokens withdrawn. I simply only care about if the treatment leads to less tokens withdrawn (and not the other way around), which is why the one-tail is still okay 🙂
I then ran multiple linear regressions and simple linear regressions using factors such as age, gender, and treatment for my independent variable. Age and gender did not seem to have any sort of relationship with the number of tokens taken out.
I will still need to discuss with Dr. Wang next week about the implications of the linear regression results, but that is my conclusion so far :).
Until next time,
Cindy
Leave a Reply
You must be logged in to post a comment.