Week 10: Debugging eHFO Bug and Processing Longer EDF Files
May 15, 2026
Hi everyone, welcome back again to one of my final blogs! This week we were able to successfully debug and fix the epileptic HFOs bug that I discussed about in last week’s blog. From there, I re-ran the 4-hour segmented EDF files (which took 8+ hours again), and now the epileptic HFOs should finally show up when we create the 4-hour data analysis plots from the mouse EEG recordings. After completing that, we kicked off the new batch of segmented EDF files from the 24-hour EEG recordings, with now we’re currently running detections and classifications on the 12 to 18 hour segment of that 24-hour EEG recording.
In last week’s blog, we saw that the eHFO detections weren’t showing up in the analysis plots, and we had to fix this immediately since eHFO and spkHFO are two of the most important biomarkers, they signify when an HFO occurs in the epileptogenic zone. While fixing this, I actually realized the issue wasn’t in the creation of the analysis plot itself, but in running the detections and classifications across all 150 of our 4-hour EDF files. Every recording’s eHFO column was 0 across all 150 of our 4-hour xlsx files when I went through them, like in the sample of a previous dataset shown below:
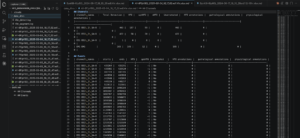
So I traced through the code and found that the eHFO model file exists and gets loaded, it initializes the classifier, and when pyHFO script: quick_detect.py –classify –device cuda:0 runs, the eHFO model is loaded onto the GPU. The eHFO inference method exists too, but then I found the actual error: the script pyhfo_quick_detect.py never actually calls it. Essentially, the eHFO classifier was ready and loaded, but the third method, classify_ehfos(), was always missing from the chain. So pyHFO was paying the cost of loading the eHFO model on every run, but never actually running it. The eHFO column in the output xlsx then just got a default zero value because the classifier never wrote any predictions.
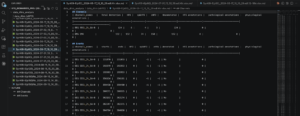
The fix was to actually classify the eHFOs with adding lines added to script pyhfo_quick_detect.py, right after the existing classify_spikes() block: “print(” Classifying eHFOs …”), backend.classify_ehfos()”. So after debugging this, I ran a smoke test of one of the 4-hour detections and classifier, and compared to its previous 4-hour detection, the eHFO column went from 0/0 across two mice EEG channels to now 3 and 150 out of 124 and 152 HFO events respectively as seen in the image below, which exactly what we’d expect once the classifier was actually firing.
Once the smoke test confirmed the eHFO classification was working, I had to re-run all of the 4-hour EDF recordings once again so we could finally see eHFO data across every EEG mouse recording in the 4-hour segments. The batch detections and classifications took around 8+ hours again, I walked through the process of running batch detections in one of my past blogs, so feel free to check that out too! After the batch detections and classifications were finished, the next step was creating all of the analysis plots of HFO detections from the segmented EEG data to find significant and important patterns. As of now, we’re still in the middle of creating those plots, so I’ll likely cover some of them in next week’s blog.
From there, we wanted to continue finding much more significant patterns and biomarkers from the 24-hour EEG recordings across all the mice at their different phases. Initially we only ran the first 4 hours of each 24-hour recording, but now we want to see what patterns show up between the 12 hour and 18 hour mark. That means segmenting 150 6-hour EDF files, so now the detections and classifications on those have been running for a while now.
Since this is one of the final weeks, I’ll likely update the next blog with the analysis plots and any significant results from the 6-hour EDF files. It’s been a great time getting to explain parts of my research project, and I’ve really enjoyed answering interesting questions and writing fun, fascinating blogs along the way! Across the summer, I’ll be heavily continuing this project, finding and analyzing true, significant biomarkers and the effects of nortriptyline, which we’ll be able to explain more deeply in our future research.
Leave a Reply
You must be logged in to post a comment.