Week 4: Topic Homogeneity
March 21, 2026
Hello everyone, and welcome back to my blog! This week, I focused on analyzing topic homogeneity across two different datasets: a dataset of X comments and a dataset of Reddit comments from the news subreddit.
Topic homogeneity measures how similar the comments with each detected community are. In other words, it tells if people in the same community are actually talking about the same thing.
How I Computed Topic Homogeneity
To calculate topic homogeneity, I started with my community graph with comments already grouped together. Then, I followed this equation for each community:
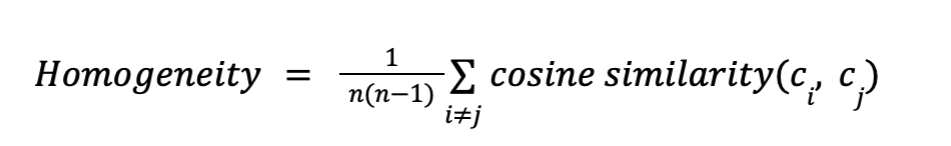
How this equation works in words is that it calculates the cosine similarity for every pair of comments possible in a community, then it takes the average of these similarity scores to create one single value showing how closely related the comments are.
This will give a value between 0 and 1 where a higher value means that discussions are more focused on the same topic, while lower values mean that communities may talk about a wider range of ideas.
Results: X Dataset
The X dataset showed relatively high homogeneity scores across most topics:
Political Campaigns and Elections: 0.728691
International Relations and Strategy: 0.673934
National Security and Defense: 0.641711
Education and Teaching: 0.634931
Research and Scientific Development: 0.634908
Economic Policy and Finance: 0.484346
Social Issues and Race Relations: 0.470881
Media, Communication, and Public Discourse: 0.466458
Overall, most communities have scores above 0.6, meaning that discussions are decently concentrated around the same ideas.
Results: Reddit (r/news)
The Reddit dataset showed significantly lower homogeneity scores:
Private Prisons: 0.468554
Tax Policy: 0.244306
Healthcare Policy: 0.200636
Donald Trump Policies: 0.193802
Economic Inequality: 0.178718
Iran Sanctions: 0.148979
Religious Freedom: 0.140398
Middle East Policy: 0.136789
Abortion Access: 0.123881
With the majority of values being below 0.25, there is more variation within each topic. Within each topic, there may be other related subtopics that people discuss, which could be the reason why scores are much lower for these communities as opposed to the communities on X.
Analyzing the Results
Higher topic homogeneity like what is seen in the X dataset means there is a higher chance of echo chambers existing, where users are constantly exposed to similar ideas within their community.
Lower homogeneity like on Reddit could mean that discussions are less isolated, and multiple viewpoints and subtopics could be discussed in the same place, which decreases the likelihood of echo chambers existing.
However, the real question is still yet to be answered. Next week, I will begin working on sentiment analysis, where I will calculate how everyone in one community truly feels about the main topic. Even with Reddit showing low scores in topic homogeneity, it could still prove to have echo chambers as I continue to work on the Echo Chamber Index.
Thank you for reading, and I will see you all next week!
Harish
Reader Interactions
Comments
Leave a Reply
You must be logged in to post a comment.
Great work from last week Harish! I was wondering how the general format of posts of selected platforms plays a role in these scores. X has a character limit, and posts tend to be shorter. On the other hand, Reddit posts can be massive rabbit holes that constantly expand on one idea. These may affect the cosine similarity used due to the trend in length. Do you think that the structural differences in text length might be skewing the homogeneity scores down for Reddit, regardless of the actual community behavior?
Hello David, and thank you for your comment!
That’s a very good point, and I thought about that as I was cleaning the data I would use. To account for that, I calculated homogeneity scores based on sentences and not full comments. That way, longer Reddit posts wouldn’t disproportionately lower the similarity score just because it has more detail or subtopics. Because of this, I think the reason Reddit had a lower score is because of how comments on Reddit naturally tend to branch out and bring in multiple topics into discussions.
These are some interesting findings Harish. I believe they are a little counterintuitive to my current intuition. X has a single “For You” tab where the algorithm recommends content. This could possibly leading to some variety, as a user could have, on the lower side, 2-3 interests, leading to less of a hyper-fixation on a single topic. However on Reddit, the existence of subreddits lead to a single discussion around a certain topic, meaning the structure of the site leads to more homogeneity. However, your findings appear to be hinting to the opposite. I wonder what the gap could be.
Hello Anav, and thank you for your comment!
I had a similar idea going into this part of my project, but I think the main difference is from where I got the data from. The r/news subreddit can be very broad in terms of discussed topics. People could be debating and making jokes, or even bringing up new ideas. On the other hand, X’s “For you” tab works with an algorithm that reinforces people’s online engagement patterns, which is a big trait in echo chambers. It is definitely a bit counterintuitive, but it might mean that echo chambers are more affected by how people interact within discussions rather than how the platforms organizes content.
Your project is so interesting for its combination of humanities and STEM. Many of the conversations you mentioned from X and Reddit are humanities-focused, whether it be politics or social issues. Finding a way to convert this into data and numbers is fascinating and a great way to compare two entirely different topics. I can’t wait to see where this goes next.
Hello Harish,
These numbers are extremely intriguing! I’m curious as to how the complexity of topic affects the comments and how they are pooled together. For a topic like “Economic Inequality”, it has pretty low topic homogeneity as expected as it’s such a broad topic that could cover multiple different people groups, countries, and situations. However, a topic like “Private Prisons”, which is much more specific and concrete, has a much higher topic homogeneity. I’m interested to see the extent to which the actual complexity and depth of the topic could affect this score!