Blog #2 - AI and the AI Composer...
April 3, 2026
Hello everyone… after a whole month… 😞
I can’t apologize enough to everyone for this horrifically long absence from blogging. I’m gonna save words and cut to the chase – there was familial turmoil followed by personal issues I’d rather not mention in a jolly blog post. In any case, from here on out, I plan to stick to the weekly schedule despite problems I’ll face in the coming month…
Anyways!!! Before picking up where I left off, I have to announce a very large pivot. After reading Koska et al.’s Tonal Harmony[1] and talking with my external advisor, I realized my older research question of comparing human-composed music and AI-generated music has too many issues with confounding factors, overly-lengthy analysis, and copyright/legal problems if I am to publish any meaningful results.
Philodump
Unfortunately, this change means I have to let go of some very interesting philosophical questions about the nature of human creativity in the context of the now-widespread use of AI in music. I suppose it’s still worthwhile to highlight the following: music technology has progressed “like never before” every decade. (For example, many of our parents knew a world without DAWs (1977), MIDI (1983), AutoTune (1997), Napster (1999), and SoundCloud (2007)). But these previous technologies enhanced humans’ capability to create and share music as a personal creative expression! We don’t get that nearly as much with AI.
Another effect of AI is that music is being increasingly ‘democratized’, and nowadays people don’t need NEARLY the same expertise as they did before to create music. In a way, that’s like ditching ice couriers for fridges and mailmen for email. But a better analogy would be ditching artist commissions for AI drawings, as it’s taking human expression and outsourcing it.
There’s also another question of true authorship. It’s long been known that humans create and make decisions based on past experiences – if AI works like we do by having a database of human art and basing decisions based on that information, isn’t AI basically a human, and therefore all of AI’s work is ultimately “humanity’s” work? And this isn’t even removed by iterations of AI work being returned as inputs, because the very origin/source of all of it is ultimately human work. Weird… what about us humans and our own ultimate source(s)… 😨
Anyways, a lot of artists nowadays, such as Xania Monet and… drumroll please… Paul McCartney(!), are starting to incorporate AI into their workflow. And who knows how many popular artists have started using AI but still haven’t disclosed it? I guess we can only see what happens to music quality over time.
If I went into this project with these background questions, my research would be cluttered and hard to quantize into some tangible data. Much of the above has a lot more to do with ethics and psychology, and is unfortunately pretty out of scope for my senior project. I’ll leave such topics to the experts!
What to Do
Now, I’ve decided to instead simply compare three different AI generation models – Suno, Udio, and AIVA – for a much more controlled and quantifiable experiment. This is the new research question: “How do different AI music generation models interpret identical compositional prompts, and what systematic differences emerge in their outputs?”
After researching the capabilities of the three models, this is the new workflow:
1: Generate 3 prompts each for 5 different genres (simple pop/EDM, classical, jazz, rock, rap; EDM/rock/rap with accompanied lyrics). Prompts will have instructions for tempo, total duration, song structure, instrumentation, as well as a “mood”.
2: Run each prompt through each model 3+ times, and rate each for the adherence to the above prompts/instructions. *Note – research by Nwaeke & Orru[2] shows that AI-generated music often interpolates between instrument sounds. This results in the side effect of noise and/or static compared to typical human-composed recordings and songs, so the loudness of this noise will be measured in dB and added as an additional measure.
3: Spectral Analysis: This would include frequency ranges (spectrogram), spectral density (centroid), and dynamic range (RMS amplitude analysis). For those who don’t know about RMS amp, it stands for the Root Mean Square amplitude, which is essentially a glorified “average loudness” of a section in a piece of music or any other signal.
4: Structural Analysis: I’ll analyze (1) the density of distinct sections; (2) the repetition rate of the chorus’s motifs; and (3) the transition smoothness through filter sweeps and risers. Admittedly, #3 is also indirectly included in RMS, but I’m putting it here for extra clarity. I’ll see if I can find a way to separate these from the noise and the raising/lowering in loudness of the base instruments. If not… oops!
5: Rhythmic Analysis: These include (1) distinct rhythmic patterns per section, defined for my purposes as a pattern of beats with at least 3 repeats across 3+ measures throughout the song (no need to be consecutive); and (2) syncopation, a.k.a. off-beat accents.
On Textural Analysis
Now, let’s get into what was promised a month ago: a more detailed explanation on the nitty-gritties of textural analysis. To compare Suno, Udio, and AIVA, I’m using three specific lenses:
Onset synchrony. According to David Huron[3][4], we can measure texture by looking at onset synchrony, which is a fancy way of asking “do the notes all hit at the same time?” High synchrony would look like a church hymn, while low synchrony would look like some funky jazz. This could be compared alongside semblant motion, i.e. parallel vs. contrapuntal motion, or more simply, “are the voices going up/down at the same time, or are they diverging/converging?”
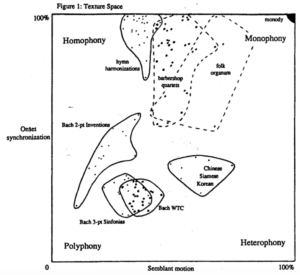
Huron’s grid of onset synchronization against semblant motion[3].
The “layer cake”. In pop and EDM, we don’t usually think about soprano or alto voices, but rather a system to identify functional layers. The “big four” are usually the base (drums), bass, melody, and harmonic filler (like fun synth pads and whatnot). I’m also adding Megan Lavengood[5]’s “novelty layer” of weird, stand-out textures that give a unique feel to each song. I want to see if one AI model is better at creating these distinct layers than the others.
Binary oppositions. This is basically contrast based on, for example, dark-vs-bright (low freqs. or high freqs. dominate), thick-vs-thin (maybe all freqs. are present, or maybe none), and pure-vs-noisy (clean equal temperament tones or distortion). This is a bit more in-depth than the Spectral Analysis portion, so it’d be interesting to get some data from here.
Thank you so much for reading. Stay tuned for fun spectrogram images!
References:
[1] Harmony, Stefan Kostka, Tonal, et al. Tonal Harmony. McGraw-Hill Education, 2017.
[2] www.ichekejournal.com, Vol.23. No.1 March, 2025. “The Impact of Artificial Intelligence on Music Composition and Production.” Icheke Journal, Jun. 2025. https://ichekejournal.com/wp-content/uploads/2025/06/10.-The-Impact-of-Artificial-Intelligence-on-Music-Composition-and-Production.pdf.
[3] Huron, David. “Characterizing Musical Textures.” International Computer Music Association, vol. 1989, Jan. 1989, pp. 131–34. https://quod.lib.umich.edu/i/icmc/bbp2372.1989.033/4/–characterizing-musical-textures.
[4] Huron, David. Voice Leading: The Science Behind a Musical Art. MIT Press, 2016.
[5] Lavengood, Megan L. “MTO 26.3: Lavengood, The Cultural Significance of Timbre Analysis.” Music Theory Online, vol. 26, no. 3. Accessed 2 Apr. 2026. https://www.mtosmt.org/issues/mto.20.26.3/mto.20.26.3.lavengood.html.
Reader Interactions
Comments
Leave a Reply
You must be logged in to post a comment.
Hey Lawrence!
Great update, I love the new and narrowed direction of your research. Can’t wait to see some of those comparison results!
Lueders