Week 4: Shifting Balance for Class Imbalance
March 21, 2026
Hello, and welcome back to my blog! This week, I tackled the problem of class imbalance in my segmentation models. After figuring out how to use rasterio to compress images, avoiding the issues with transferring my model to my local computer, I began to train the models. The biggest problem i noticed, and the one I anticipated too, was class imbalance. Both my road detection and damage assessment model suffered from this. The road detection’s predictions for the road class would never exceed 0.5 probability, and while the house damage assessment can tell the boundaries of houses, it only detects undamaged houses. These are textbook cases of class imbalance, because there are so many more pixels of background and/or undamaged houses—because they are the norm—that the model can assume any pixel belongs to the majority class while still being mostly correct.
(Left: reference image, Middle: ground truth mask, Right: model’s predictions)


This week, I focused on the road detection UNet to work on a simpler case of class imbalance. Come with me to learn about solutions to this well-known machine learning problem!
Shifting Representation: Under- and Over-sampling the Dataset
This is probably the most intuitive solution to class imbalance. If the amount of pixels one class is too small, just show more of it (compared to the other class/es)! Then the model won’t treat it as an outlier. I checked the road vs non-road pixel distribution, and the roads were indeed undersampled by a large amount!
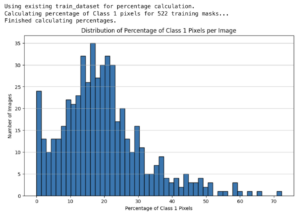
Most of the images have 0.2 or less of all pixels classified as roads. Thus I filtered the images so that when training, it’d only use images that have 0.2 or greater proportion of road pixels. Now, it detects roads with slightly greater confidence. However, the probability of detecting the road was still not greater than 0.5, meaning the model still “thinks” everything is more likely to be background than road. (Where the predictions are this turquoise color, that means the probability the pixel is road is greater than 0.2, but less than 0.5)

I played around with increasing and decreasing the training dataset size, but it roughly stayed the same throughout. I did struggle at one point when the dataset took way too long to start running because the filtering took place when initializing the dataloaders for the Pytorch model, causing 6-7 minute delays on T4 GPU before the model even starts training. I mitigated this by downloading all the image-label-pairs with road representation into a separate drive folder.
Shifting Error: Weighted Loss Functions
The loss function is a way of telling how far off the model’s predictions are from the ground truth. Thus, if we penalize the model more for messing up on the minority class, it will adjust its weights to make a greater effort to learn it.
My attempt at this did improve the model’s accuracy at not detecting other random pixels as the road, but its overall probability for the detected road pixels still didn’t exceed the 0.5 threshold needed to segment that area as road.

Shifting Gears: Other Changes I Made
At this point, I decided to tackle the other issues with this model. I realized that there was no point in making the U-Net detect two classes when I could just get the probability for one class (roads) and use a threshold like 0.5 as the cutoff between road and non-road.
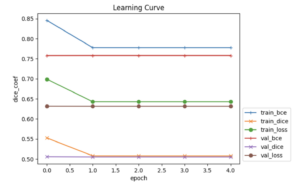
Afterwards, I noticed that its learning curve (the curve of loss plotted over training epochs*) consistently plateaus after the first epoch, which means the learning rate may be an issue, either too high or too low. The learning rate refers to how much a model updates its weights in response to errors. I noticed that my learning rate scheduler wasn’t being applied, since it’s step size is 30 epochs while I was training the model with only 5 epochs (there’s no point in waiting longer if the results won’t change over time…)
*epoch: one complete pass of the entire training dataset through a model, where a model updates its weights and saves its best configuration.

When i lowered the step_size, the results were more “unclear”, with probabilities stuck at or around 0.5.

When I raised the step_size (I found 60 to be good), the pixels actually started differentiating themselves between road and background. I was finally getting the model to detect roads confidently, and to a good enough accuracy.

(Excuse the change in image formatting)

Observations and Insight
Could I have done this by reading the documentation on what lr_scheduler did instead of spending a lot of time brute forcing? Yes. But I think the visual representation I got helped with my understanding!
However, my learning rate still plateaus after the first epoch, and the loss values are still decently high. My question for you, readers, is how can I improve the model to address this? I’ve been inspecting the model visually a lot of times up to now, but the numbers look pretty concerning, with Binary Cross-Entropy (BCE) at around 0.8.
After all this training, I noticed that the model seems to use color as the identifying feature, It’s not great at recognizing cars as part of the road, and sometimes detect flat gray rooftops as roads. Although failing to detect cars isn’t fatal—possibly even beneficial—when it comes to earthquake rescue (knowing where rubble or broken cars blocks the roads can prevent you from taking a wrong turn), misreading roofs as walkable roads wouldn’t be good. If any of you know what other parameters I can tune or architecture changes I can do to make my UNet learn the difference between roofs and roads, I’d like to hear it too!
Next week, my goal is to apply what I learned about tackling class imbalance with the house damage assessment UNet model, and hopefully start training the other machine learning models I wanted to use.
Works Cited
Shao, Yang, et al. “Deep Learning for Remote Sensing Mapping of Roads, Sidewalks, and Bicycle Lanes in Bogotá.” Remote Sensing Applications: Society and Environment, 23 Mar. 2026, p. 101993, www.sciencedirect.com/science/article/abs/pii/S2352938526001266, https://doi.org/10.1016/j.rsase.2026.101993.
Ritwik Gupta, et. al. 2019, xBD: A Dataset for Assessing Building Damage from Satellite Imagery, arXiv, https://arxiv.org/abs/1911.09296
Reader Interactions
Comments
Leave a Reply
You must be logged in to post a comment.
Hi Yujie, great progress this week! I didn’t expect class imbalance to be such a large issue in geospatial data processing, as I’ve never experienced it myself. Maybe I should go back to some of my old projects, and see if it affected my results without me noticing. I was wondering, did any of the literature you reviewed discuss class imbalance, and might they have hinted at some way to tackle it?
Hi Yujie, it seems like you made some really good progress this week! It just so happens that I’m also trying to work with class imbalances right now, so reading this was really helpful in getting some ideas for my own project. You mentioned that your model was having some trouble differentiating between roofs and roads because of the coloring. If it’s relying heavily on color, could that point to more of a data/representation issue rather than a tuning one? Are there any augmentations that could reduce color dependence or force the model to rely more on structure instead? I don’t have much image-recognition experience, so I’m not quite sure how it works. For the model, I think some architectural or loss function changes could help the model distinguish between two similar-looking objects (like maybe changes that handle class imbalance like how classes are weighted, or emphasize spatial consistency?). There might be some literature on this that could be useful, but I’m excited to see where this goes next week! 🙂
Hi Chloe,
You’re make a great point! I’m am actually currently working on making the U-Net detect the houses themselves, then incorporating it into the damage assessment stage. I’ll share my findings on that in the upcoming week 6’s blog.
Hi Yujie, your project looks like it’s going great! I have a quick question on the idea of class imbalance. Is it the idea that there are certain variables or factors that are more weighted than another, causing the model to misclassify data? Thank you!