Week 7: Ultimate Battle of Performance Metrics
April 11, 2026
Hi and welcome back to my blog! This week, I pit the three models I’ve been working on against each other to find out how well they perform compared to each other! If you’ve been reading my past few blogs, you won’t be surprised by the results.
What are the Metrics
Before I go into the data tables, I’ll explain which metrics I’m using so far.
IoU: Intersection over Union
Also known as the Jaccard index, this metric’s name is pretty self-explanatory. You would simply take the area of intersection between one class’s predictions and that of the labels, next taking the union, then dividing. This is a good measure of how accurate the segmentation area is in computer vision models. If you’re more used to using confusion matrices, it would be TP / (TP + FP + FN) where TP is true positive, FP is false positive, and FN is false negative.
F1 Score
The F1 score is a metric more generally used in machine learning that measures a classification model’s accuracy by calculating the harmonic mean of precision and recall. The resulting number ranges from 0 to 1, 1 being perfect. Precision measures the accuracy of positive predictions (for a pixel belonging to this class), while recall measures the ability to identify all relevant positive predictions. Precision is calculated as TP / (TP + FP) , while Recall is calculated as TP/ (TP + FN)
Here are the results, with the best-performing model highlighted!
Road Detection Model Comparison
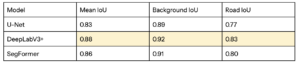

All three models perform very well on road detection, all reaching well above 0.8 IoU and F1 score. Even though SegFormer is the most advanced architecture, surprisingly DeepLabV3+ is the most successful model. Since all the models have metrics very close to each other, only differing at the hundredth point, it could likely be due to random differences in model training, or not optimizing all the parameters for each model.
Damage Assessment Model Comparison
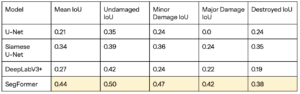
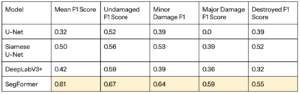
Here it’s much more predictable. The SegFormer outperforms both U-Nets and DeepLabV3+ very noticeably, likely because the SegFormer’s transformer architecture allows it to capture more context, learning features that are less obvious. Also note that DeepLabV3+ performs slightly worse than Siamese U-Net, but better than normal U-Net. This is likely evidence to show that the Siamese architecture to incorporate pre-disaster data really does help the model learn features better.
U-Net House Detection
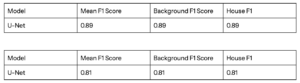
Here’s the UNet house detection metrics as well. It’s pretty successful, just like it would be successful for roads, since the tasks are almost the inverse of each other.
Reflection…
Now that I’m finishing up the first stage of my project, comparing the effectiveness of the three models and learning how they learn, I want to stop and reflect on what I accomplished, what opportunities I missed, and what I’ll do going forward.
This is one of the first projects where I’d actually explored and experimented with deep learning models extensively, and I was actually able to see improvement in the models when I make changes to it, which I’m proud of. I learned a lot about the strategies people employ to make stronger, smarter machine learning models. I’m extremely grateful to my internal and external advisors that have guided me and provided critical suggestions along the way.
I now realize the scope of my project is probably more than I should have taken on. I was able to do everything at the end, but I fear my reliance on pre-trained models (specifically SegFormer) and pre-labelled data prevented me from learning more about the remote sensing field and the scientific method.
…and Looking Forward
In the next few weeks, I am going to optimize the models. Since SegFormer is the best so far, I’ll focus on that, by attempting to build a SegFormer model from scratch instead of using the current pre-built one. (Thanks Chloe for the suggestion! Context in week 5’s comments.)
Additionally, I hope to measure the models’ GPU computational efficiency, since it would be important to know how fast a model can respond to satellite data of earthquakes in real time. I’ve moved my U-Net and DeepLabV3+ models to my local machine’s VSCode and I’ve downloaded a GPU performance tracker which is ready to gather data for. Currently, I am struggling with moving SegFormer into VSCode, because even with the exact same code (and almost the same package versions), I am getting this error in VSCode while not in Google Colab.
RuntimeError: view size is not compatible with input tensor’s size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(…) instead.
This happens when the model’s built-in code runs loss.backward(), and doesn’t change whether I use my mac’s MPS or CPU. I think this might be fixed if I build my own SegFormer, but if anyone knows a quicker fix to this, I’d be really grateful!
Reader Interactions
Comments
Leave a Reply
You must be logged in to post a comment.
Hi Yujie, I’m glad you were able to gain some clarity regarding your models’ performances. I have one question. Do you think building a new SegFormer model from scratch will fit in your current timeline, or do you think you might have to condense the project scope in order to make time for this? Looking forward to next week’s updates!